浅谈Rust数据所有权
Rust的目标之一,是能够作为一门内存高效且内存安全的语言。本文我们将重点关注Rust关于“内存高效”的语言设计,让读者能够建立起对Rust的基本认知。
内存高效
一个不恰当的比喻:将一座房子卖给另一个人的时候,究竟是从头开始建一座同样的房子,然后把这座新房子的房产证交给买家的方式效率快,还是直接将现有的房子的房产证交给买家快?答案不言而喻。
什么是内存高效呢?一般来说,有以下几个要点:
- 小内存占用:程序在运行过程中使用的内存较少,这可以降低内存压力,提高系统的整体性能。
- 快速响应:由于内存占用较小,程序加载和执行速度更快,用户等待时间更短。
- 节省硬件资源:内存高效的程序可以在有限的硬件资源下运行得更好,延长设备的使用寿命。
- 适应性强:在低配设备或内存紧张的情况下,内存高效的程序仍能正常工作。
为了达到上述的目的,程序通常会采取以下的方式实现内存高效:
- 优化数据结构和算法:选择合适的数据结构和算法可以显著减少内存消耗。例如,使用哈希表代替数组进行查找操作,或者使用动态规划方法解决重复计算问题。
- 复用内存:尽量避免不必要的内存分配和释放,例如使用池化技术管理内存块,或者重用已存在的内存区域。
- 减少冗余数据:避免存储重复或不必要的数据,例如使用引用或指针共享大对象,或者在需要时才生成临时变量。
- 延迟初始化:只在真正需要时才为变量分配内存并初始化,而不是一开始就全部创建。
- 及时释放内存:当不再需要某个对象时,尽快将其从内存中移除,以防止内存泄漏。
让我们先聚焦“复用内存”。程序在运行的过程中,势必会有数据产生。常规来讲,数据会程序空间中的栈上或堆上产生,并占用一定的内存空间。如何更好使用这些内存中的数据,不难想到,尽可能的复用已有的内存区域,而不是频繁的创建和销毁内存区域。那么,在Rust中是如何对“内存复用”这块进行设计的呢?
赋值与移动
我们首先给出下面两段代码:
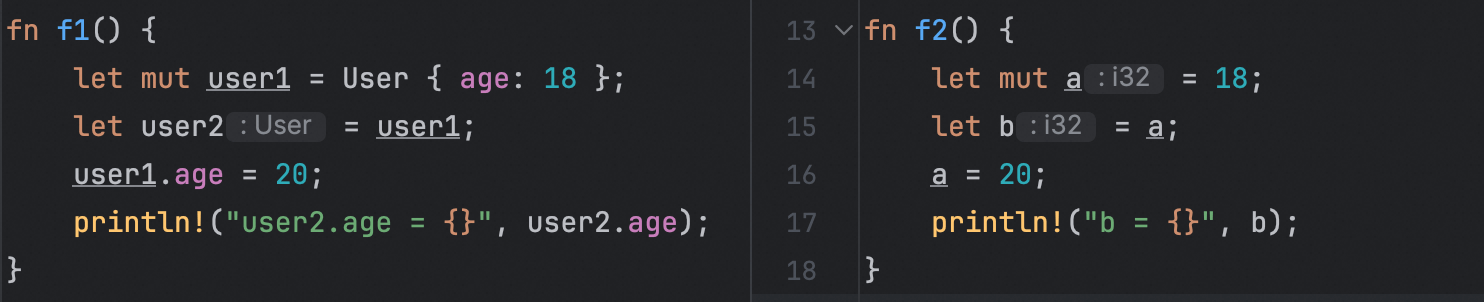
- 左边f1代码,将一个i32类型的变量赋值给另一个i32类型的变量,然后修改自身的值。
- 右边f2代码,我们首先定义了一个User结构体,该结构体包含一个
age字段;然后,我们采用和第一段代码类型的赋值流程。将变量user1赋值给变量user2,然后尝试修改user1中的age值。
我们尝试对两段代码进行编译。第一段关于f1方法的代码能够正确编译。对于该方法执行的过程,我们可以用如下的图来表示变量a、变量b在内存中的变化情况:
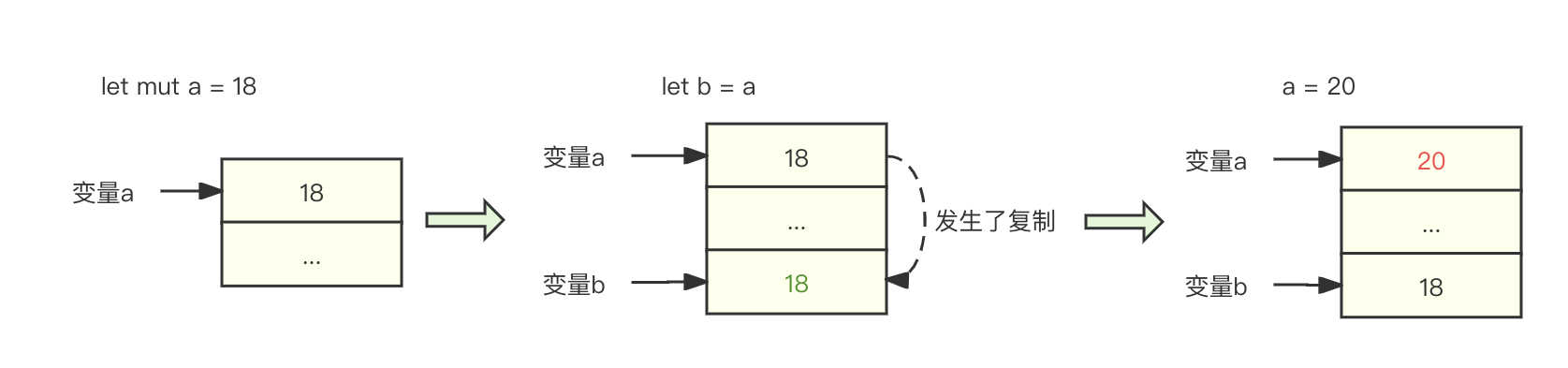
也就是说,Rust在处理i32变量赋值的时候,会将变量a的值复制一份,然后将变量b指向这个复制的变量。至此以后,变量a与变量b将再无关联,它们各自指向了内存中的不同数据。
然而,在实际编码过程中,我们不可能永远只用i32、f64、bool等Rust中的基本数据类型。根据场景,我们总会定义、创建和消费一些struct结构体数据,就像上面的f2方法一样。然而,当我们编译f2代码的时候,却会出现编译错误:

报错描述信息比较多,让我们首先聚焦4、5行的编译信息。第4行下提到:value moved here(值在此处被move移动);第8行下报错提到:value partially assigned here after move(在move移动以后对值进行局部赋值)。
两句话都提到了一个词:move移动。在进一步解释报错前,我们先抛出Rust中编程的一个基本原则:
在Rust中,除一些基本数据类型的赋值是copy拷贝操作以外,其他复杂结构(譬如结构体等)的赋值默认行为是move移动操作。
学习Rust的读者,一定要铭记上述这段话,它是贯穿了整个Rust语言的,很多的特性(包括生命周期与借用)都基于这一基本原则而扩展引申而来。
如何理解move移动
在构造一个数据的时候,通常会使用一个变量进行绑定(就像上面的let mut a = 1;或let mut user1 = User { age: 1 };)。第一个绑定到该数据的变量会拥有了该数据在内存中的所有权(ownership)。当我们将一个变量a赋值给另一个变量b的时候,Rust会将该变量a所有持有的所有权move给变量b。
我们可以把内存中的数据比喻成一座“房子”,那么所有权就可以比喻为:同一时刻,只能有一个变量所持有的“房产证”。而move移动,则是将这座房子的房产证交给另一个变量。
那么,对于上面的代码流程,我们可以想象为如下流程:
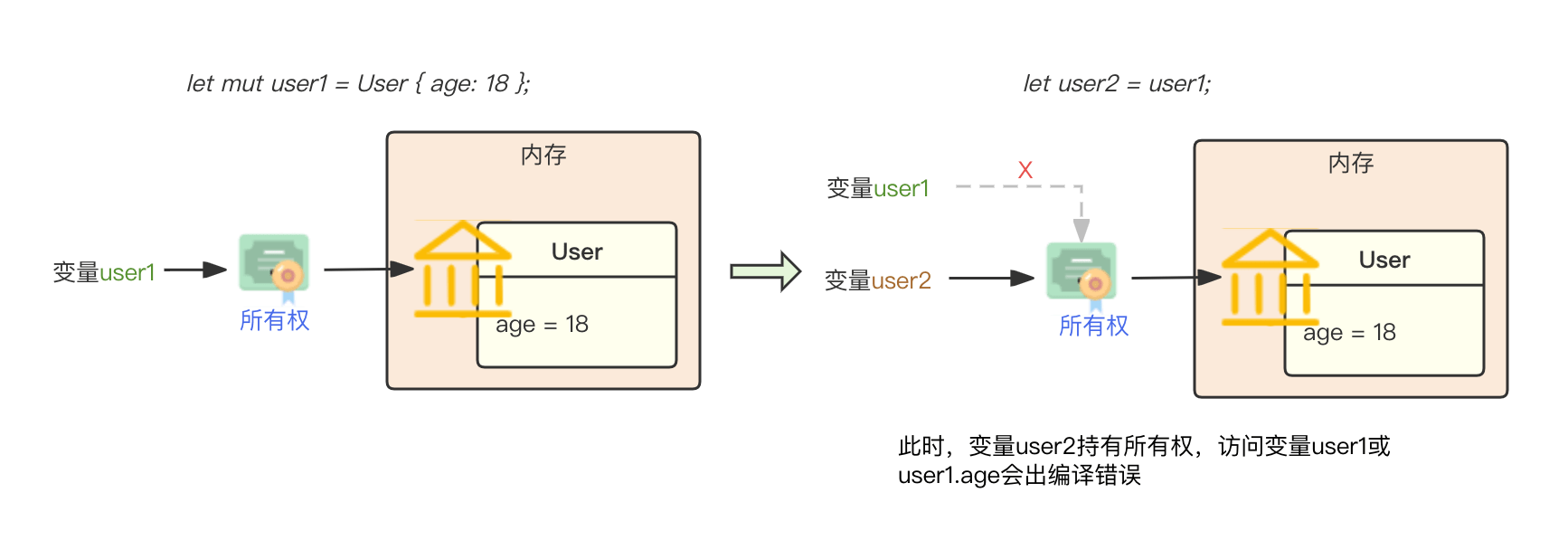
变量user1绑定到了一个User结构体数据,此时,user1拥有User结构体数据这座“房子”的“房产证”;当我们将user1赋值给user2的时候,user1所拥有的“房产证”就被move移动到了user2身上。那么接下来我们再对user1进行修改的时候,很明显,user1压根儿就没有这座“房屋”的“产权”,自然无法对房屋内部的数据(此处就是age字段)进行读写。
注意,没有所有权,对内存中的数据的读和写操作都无法进行,而不仅仅是写操作。
此时,读者会疑惑,按照这样的思路。为什么第一段f1方法代码中,将i32类型的变量a赋值给变量b是在内存中进行了单独的复制操作,而没有进行所谓的所有权移动操作呢?
其核心在于,Rust中的基本类型数据,在内存中的创建是“廉价”的。尽管基本类型在不同的操作系统平台上可能占有不同的字节数,但即使是64位操作系统,最大的i64、f64等基本类型也只占用8个字节,这些数据可以方便快捷在的在内存中进行按位赋值创建。然而,对于结构体这种复杂数据类型,在内存中创建的代价是“可能”昂贵的。
这里用“可能”,是因为如果你的结构体非常简单,譬如:
struct Data { val: bool },使用size_of函数计算出的结构体大小只占用1个字节,这样的数据在内存中进行复制操作也并不会“昂贵”。
针对可能昂贵的数据复制行为,Rust采取的策略是对于这类复杂结构数据(有时候也叫复合结构数据),变量赋值默认使用move移动语义。将复杂结构对象比做房屋,无论建造的房屋是大是小,Rust默认不会在进行变量赋值的时候替你修一栋相同的房屋,然后把你新建造的房屋的产权交给新的变量,而是简单的将房产证交给新变量,而原来的变量就失去了房产证,即它失去了所有权。
总结来说,Rust语言的愿景之一是希望能成为一门“blazingly fast and memory-efficient(速度极快,而且内存效率高)”的语言。为了达到这个目的,Rust语言在非基本类型变量赋值的时候,默认采用move移动语义,采取这样的方式可以避免在内存中频繁地进行昂贵的数据构造,而是复用内存中的数据。
关于方法参数与返回
有的时候,我们可能调用某个方法来获得一份数据:
1 | fn get_user() -> User { |
get_user的实现我采用了最冗余的写法:我们使用temp绑定了一个User数据,然后返回了该temp变量。
在调用点,我们使用变量user来绑定了get_user的返回值。这段代码是没有编译问题,也能够正确运行。接下来,让我们分析这个过程中,关于User { age: 18 }的移动是怎样进行的。
在get_user方法中,我们首先在内存中创建了一个User数据,然后通过let temp = ...,让变量temp获得了内存数据的所有权。接着,我们将temp返回给调用点,并将其绑定到变量user。在这个过程中,需要注意,变量temp在内存中的所有权被move移动到了变量user身上,而变量temp本身会在get_user函数调用结束后被销毁,但User结构体内存数据依然存在,它此时被user所拥有。这段逻辑可以想象成,在get_user方法中修建了一座房子,并且把房产证交给了变量temp,而随后,函数返回的“瞬间”,变量temp将“房产证”交给了变量user,同时变量temp自己被销毁,而那座房子并没有被销毁(因为还有变量拿着房产证)。
如果我们在get_user方法中,创建了User的数据,但不做任何返回,一旦方法结束后,temp变量所持有的内存数据就会被销毁。也就是说,持有所有权的变量在其销毁后,如果所有权没有转移走,那么对应的内存数据就会销毁。
让我们再来考虑方法入参。假设有如下一段代码:
1 | struct User { |
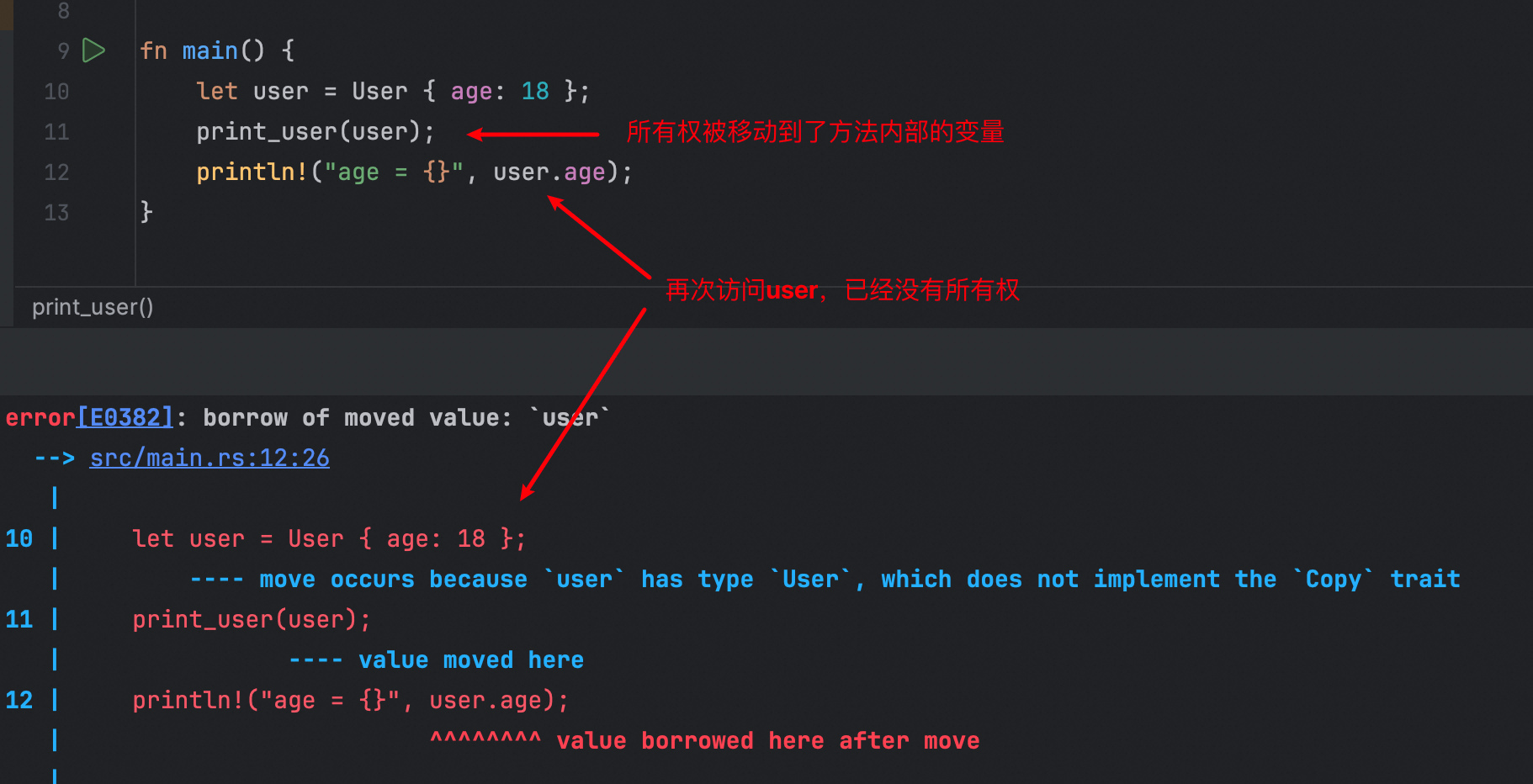
print_user方法接收一个User类型的参数,并在内部打印user.age。在main方法中,我们先创建User实例,并绑定到变量user上;接着我们调用print_user方法,并将user变量作为入参传入。这里有一个十分关键点:变量user本来持有User实例数据的所有权,由于作为函数的参数传递到了print_user方法内部,此时,会发生所有权的移动,会将所有权从原来的变量user上,转移到方法参数的user上。可能有的小伙伴还不太明白,让我们适当修改下代码:
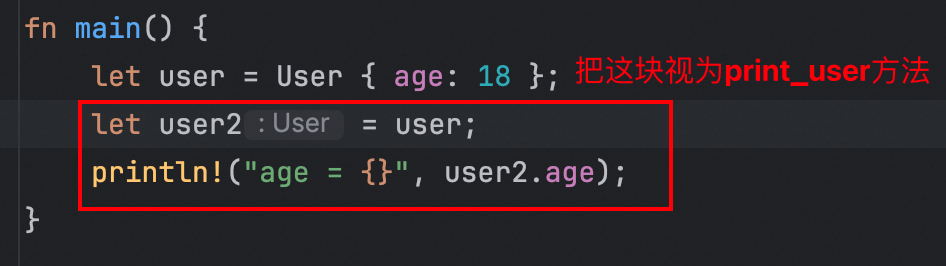
这段代码中,我们将print_user“展开”到了main方法中。此时,就不难理解发生了什么。变量user赋值给了变量user2,相当于原来的将变量user作为参数传递到print_user方法中,绑定到了参数user。所以,这里也同样发生了移动。
基于所有权的移动,上述的代码中将user传入print_user后,后面的代码自然也无法进行访问了:
看到这里,有小伙伴会有这样的思考:某些场景下,我们确实需要将数据传入某些方法进行使用,方法结束以后再回来使用。如果参数传递是移动语义,应该怎么实现我们需要的场景呢?
方式一就是我们可以拷贝一份数据,传给方法。由于拷贝需要重新创建一个全新的数据,并用新的变量绑定,很明显在占用空间较大的数据进行复制时是不符合内存高效的期望的;
方式二则是,既然所有权通过方法参数移动到了方法的参数上,那我们可以在方法结束以后,交还给调用点,就像下面这样:
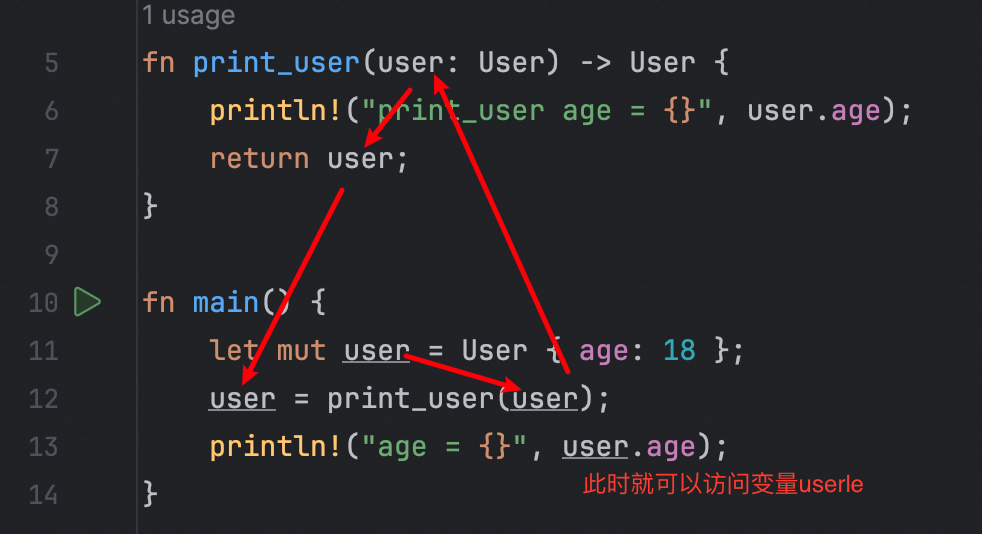
也就是说,我们将print_user修改为了将user再次返回,同时,外部代码再次使用user变量接到print_user方法返回的数据的所有权。这样一来,所有权又交还给了变量user。
当然,方式二同样也存在问题。这里仅是对一个数据的所有权的转移。如果一个方法的入参很多呢?比如,有一个方法get_total的入参如下:
1 | fn get_total(u1: User, u2: User, u3: User) { |
为了返回所有权,我们需要将u1、u2、u3都返回才行,尽管我们可以使用Rust中的元组(tuple)来完成多值返回,但同样十分不优雅!

难道就没有更加优雅的方法了吗?有没有一种我们能够访问某个数据,同时不会拿到这块数据所有权的方式吗?用房子的比喻,有没有一种方式,我们没有必要一定要持有这个房子的房产证才能进入房子去看一眼?答案是肯定的,Rust中存在一种叫做“借用”(borrow)的机制。不过,为了让Rust同学更好的消化本文,笔者决定将这块的内容放在后面进行介绍。
总结
本文简单的介绍了关于Rust的一个核心概念,数据所有权(ownership)以及它的相关机制。这块的概念完全不用死记,我们只需要从实际“内存高效”的角度出发:为了实现内存高效,我们考虑数据的产生尽可能是短暂的,而数据的使用尽可能是长期的。通过赋值操作传递数据(这里特指非基本类型的复杂数据)我们考虑不要真的复制一份,而是对这块数据建立一个标签,也就是所有权,并将所有权传递给另一个变量。当然,所有权无法满足很多情况下的数据访问,于是,Rust引入了借用机制,借用机制可以让我们在数据访问时,不必将数据的所有权传递给另一个变量,而是借用,这一点将会后面的文章进行介绍。