Linux Bash命令杂记(tr col join paste expand)
tr命令
tr命令可以将输入的数据中的某些字符做替换或者是作删除
1 | tr [-ds] STR |
col命令
1 | col [-xb] |
join命令
用于对两个文件按照某一个字符或者字段进行按行连接
1 | join [-ti12] file1 file2 |
paste命令
1 | 直接讲两个文件中的数据按行连接 |
expand命令
1 | expand [-t] file |
tr命令
tr命令可以将输入的数据中的某些字符做替换或者是作删除
1 | tr [-ds] STR |
col命令
1 | col [-xb] |
join命令
用于对两个文件按照某一个字符或者字段进行按行连接
1 | join [-ti12] file1 file2 |
paste命令
1 | 直接讲两个文件中的数据按行连接 |
expand命令
1 | expand [-t] file |
数据流重定向
1 | 标准输入(stdin):代码为0,使用<或<<; |
如果想要一般输出与错误输出同时输入到某一个文件,如果采取如下的方式进行输出是错误的:
1 | 输出数据 1> list 2> list |
如果按照上面的方式输出到list文件中时而没有采用特殊的语法,会因为两个输出进程的同步问题,导致正确的数据与错误的数据可能会交叉的输入到list文件中。正确的方式应该如下:
1 | 输出数据 > list 2>&1 |
命令执行&& ||
1 | cmd1 && cmd2 |
cut命令
cut命令按行数据进行处理,常用的方式如下:
1 | 参数 -d -f(组合使用) |
sort命令
1 | head -4 /etc/passswd |
last命令
1 | 该命令用来列出目前与过去登录系统的用户相关信息 |
uniq命令
1 | last | cut -d ' ' -f 1 | sort | uniq |
务必注意,uniq命令是通过叠加去重相邻的字符串,如果你不首先进行排序,那么会出现下面的情况:
1 | 1 root |
wc命令
1 | wc [-lwm] |
tee双向重定向
由前面的数据流我们可以知道,我们在将数据定向时,如果不采取特殊的操作,数据要么输出到屏幕,要么输出到文件或者是设备中,没有办法,既输出到屏幕有输出到文件中;又或者是,我们想要对数据进行处理存放到一个文件中,但是同时对原始数据又存到另一个文件中。使用tee命令,我们就可以做到。
例如,我们使用last命令首先要把数据存放到last.log中,同时要对用户去重并输出到屏幕上:
1 | last | tee [-a 追加] last.log | cut -d ' ' -f 1 | sort | uniq |
前情提要,如果系统中存在两个都实现了同一接口的类,Spring在进行@Autowired自动装配的时候,会选择哪一个?如下:
1 | // 一下两个类均被标记为bean |
此时再次运行测试类会发现,FAILD并且报错:
Unsatisfied dependency expressed through field ‘playable’; nested exception is org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type ‘zhen.Playable’ available: expected single matching bean but found 2: CD,video // 找到了两个都bean都能匹配
自动装配歧义性问题
上面的异常就是出现了歧义性。Spring为我们扫描了我们代码中的bean(这个部分是没有问题的),但是,在自动装配的过程中却由于歧义性而报错,并且,造成这样的歧义性还有由于Autowired这个注解仅仅按照类型进行装配——上面的CD与Video都实现了Playable接口,Autowired注解仅告诉Spring在测试类中的playable接受一个Playable类型的对象但是这里有两个bean:CD、video都是Playable类型的,所以Spring不知道。
为了解决这个问题,我们需要通过一定的手段来限定:
1 | 声明首选的bean |
声明首选的bean
根据名字我们很容易理解,就是声明在有歧义性情况下,Spring到底选择哪一个bean来装配。方式就是在bean组件下添加@Primary注解,例如在原先的CD的@Component下加上首选注解,再次运行测试代码,PASS。但是,这种方式通常只在同类型bean较少的或者是系统简单的情况使用,而且还存在一个情况:假如目前有两位开发人员,在各自的环境编写bean,他们都希望自己的bean是Primary的,都加该注解,实际上还是会报错,因为系统现在同样有两个Primary bean,Spring还是不能判断选择哪一个bean注入。
限定自动装配的bean——@Qualifier注解
首先,我们可以通过在@Component中加入字符串来更明确的指定bean id而不是使用Spring的默认bean id策略。就像如下:
1 |
|
当这样指定以后,我们在自动转配的地方,使用@Qualifier(“指定id”)来限定我们要注入的确定的bean:
1 | ... |
再次运行不会报错。
关于@Qualifier,最佳的情形应该是来标记bean特性。但是,如果多个bean都有相同的特性,都是用了相同的标记的@Qualifier注解,那么同样又会出现歧义性问题。所以我们又要添加新的@Qualifier注解来进一步限定,这样做没有问题,但是Java语法规定,不允许在同一条目上重复出现相同类型的多个注解。你不能这么做:
1 | // 编译器会报错 |
为了结局这样的问题,我们可以创建自己的注解:
1 | //字段注解 |
如此定义了注解以后,我们就可以在原先的@Component下如下定义:
1 |
|
并且在测试类下如下声明:
1 |
|
测试通过!
Spring中的Bean是一个很重要的概念。Spring作为一个Bean容器,它可以管理对象和对象之间的依赖关系,我们不需要自己建立对象,把这部分工作全部转交给容器完成,具有低耦合,对代码没有侵略性。
Linux是一个多用户系统,但是对于一个多用户共存的系统中,当然不能够出现用户相互越权等一系列的安全问题,所以如何正确的管理账户成为了Linux系统中至关重要的一环。
前期准备
1.配置hostname(可选,了解)
在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(pretty)。“静态”主机名也称为内核主机名,是系统在启动时从/etc/hostname自动初始化的主机名。“瞬态”主机名是在系统运行时临时分配的主机名,例如,通过DHCP或mDNS服务器分配。静态主机名和瞬态主机名都遵从作为互联网域名同样的字符限制规则。而另一方面,“灵活”主机名则允许使用自由形式(包括特殊/空白字符)的主机名,以展示给终端用户(如Linuxidc)。
在CentOS7以前,配置主机的静态hostname是在/etc/sysconfig/network中配置HOSTNAME字段值来配置,而CentOS7之后若要配置静态的hostname是需要在/etc/hostname中进行。
进入Linux系统,命令行下输入hostname可以看到当前的hostname,而通常默认的hostname是local.localadmin。
本次试验环境在CentOS7下,所以我们编辑/etc/hostname文件,试验hostname为:hadoop.w4ng,填入其中,重启Linux,可以看到已经生效。
2.配置静态IP
同样,在CentOS7以后,其网卡配置已经有原先的/etc/sysconfig/network/network-scripts下面的ifcfg-eth0等改名为乐ifcfg-enpXsY(en表示ethnet,p表示pci设备,s表示soket)

本人这里有两个ifcfg文件是因为配置了两块网卡分别做NAT以及与虚拟机Host-Only两个功能,实现双网卡上网
打开ifcfg-enp0s8,配置如下:
1 | DEVICE=enp0s8 #设备名 |
3.配置hosts
打开/etc/hosts
配置为如下的:
1 | 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 |
配置hosts的理由是后期hadoop配置中相关的主机填写我们都是使用域名的形式,而IP地址与域名的转换在这里进行查询(还有DNS,但是这里不讨论)。
4.关闭防火墙
CentOS7与6的防火墙不一样。在7中使用firewall来管理防火墙,而6是使用iptables来进行管理的。当然,我们可以卸载7的firewall安装6的iptables来管理。本人就切换回了6的防火墙管理方式。
1 | [root@localhost ~]#servcie iptables stop # 临时关闭防火墙 |
5.JDK与Hadoop的安装
下载JDK8
下载Hadoop3-binary
下载完毕将文件传到主机中。
在/usr/local/下创建java文件夹,并将JDK解压至该文件夹下。
在根目录下创建/bigdata文件夹,并将Hadoop解压至其中。
1 | 解压命令 tar -zxv -f [原压缩文件.tar.gz] -C [目标文件夹目录] # 实际命令没有中括号,其次,命令参数重-z对应gz压缩文件,若为bz2则使用-j |
在JDK解压完成后,在~/.bash_profile中配置环境变量 点这里看/etc/bashrc、/.bashrc、/.bash_profile关系
1 | export JAVA_HOME=/usr/local/java/jdkx.x.x_xxx |
配置完成,保存退出并 source ~/.bash_profile
hadoop无需配置环境变量
6.配置hadoop
在hadoop的home下,进入etc文件夹,有五个主要的文件需要进行配置:
1 | hadoop-env.sh |
基本配置如下
1 | 1.配置 hadoop-env.sh |
然后配置相关服务启动过程中需要的配置变量:
进入${HADOOP_HOME}/sbin中,在start-dfs.sh与stop-dfs.sh中添加字段:
1 | HDFS_DATANODE_USER=root |
在start-yarn.sh与stop-yarn.sh中添加:
1 | YARN_RESOURCEMANAGER_USER=root |
配置完成以后,进行hadoop的文件系统格式化,执行
1 | ${HADOOP_HOME}/bin/hdfs namenode -format |
最后是启动服务:
1 | 执行${HADOOP_HOME}/sbin/start-all.sh # 他会去调用start-dfs.sh与start-yarn.sh |
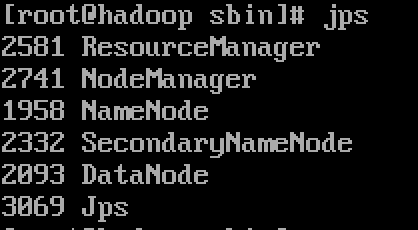
根据配置中我们都是配置的root用户,显然需要我们以root身份进行,且过程中需要root密码。当然,通过ssh免密可以方便很多。启动完成以后,命令行中使用jps命令打印Java进程,会看到下图五个进程(忽略Jps进程):
当然,Hadoop在服务启动以后以提供web端:
1 | visit hdfs manage page |
最近开始学习Spring,在看《Spring实战4th》3.3“处理自动装配的歧义性”那一部分时,书上提到(也从网上看到了类似的用法):
通过在一个类上加注@Component以及@Qualifier(“x”)可以为其配置限定符来标识区分同一个接口下的不同实现类,用以在需要进行@Autowired自动装配的地方使用@Qualifier(“x”)来指定特定的实现类对象bean。
尽管从Mac的Terminal可以看出,macOS与UNIX、Linux或多或少都有血缘关系(shell、bash等),但是在mac进行Linux开发,或者把macOS直接当作Linux来使用依然是说不过去的,这其中包括一些命令行的使用,一些基本的文件夹体系等(如,在Linux上的/home目录与在macOS下的/Users)不一致。如果想要在macOS上进行Linux的学习,或者进行Linux开发,最完美的方案自然是安装虚拟机。
众所周知,在Java中,存在着值比较与应用比较两种情况。例如,如下的比较,可以根据值比较与引用比较来跟容易的判断出结果来:
1 | int a = 123; |
这里,a与b由于是基本类型,所以Java在比较的时候直接就是按值来比较,而下面的s1与s2则是由于分别指向内容为“123”的字符串对象引用(关于string的细节,见本人的另一篇文章),而这两个字符串的地址并不一样,所以结果是false。
那么,今天要讨论的是,对于Java自动拆装箱的问题的深入探讨。如下所示,请问结果是什么呢?
1 | Integer a = 666; |
结果是false,您可能会说,这有什么好问的,Integer对象的比较,引用的比较,而这两个只是值相同,而对象不同的Integer对象罢了,所以当然为false。好,那么我再问你,下面的结果是什么?
1 | Integer a = 100; |
您可能说,哇,当我傻吗,当然还是false了。可是,结果是true。
为什么同样的情况下,当值变小了,结果就变为true了呢。
其实,Java中,对于可装箱的对象类型,都存在一个1字节的范围:-128到127。在这个范围类的数字,Java认为是常用的数字,所以自动进行了值比较,而不是进行引用的比较。所以,无论是Long还是Integer,只有你的值在-128到127,这两个对象的比较直接按照其所存储的值来进行。就像如下的情况:
1 | Integer a = 128; |
关于String相关内容的学习,历来都是Java学习必不可少的一个经历。
以前一直想要好好总结一下String的相关的知识点,苦于没有时间,终于在今天有一个闲暇的时间来好好总结一下,也希望这文章能够加深我对于String相关内容的理解(ps:在我看来,学习某些知识点的时候把学到的想到的都记录下一方面能够加深自己学习印象,二者能够锻炼锻炼我的文笔)